Intro
In
Part 1 we gave a brief overview of unit tests and when to use them. In
Part 2 we learned how to create our own unit tests in C# and Visual Studio using MSTest. This week we'll cover a couple tips and tricks to get you really humming with unit testing.There's a ton to unit testing, so please stick with me here! There will be at least one more unit testing article after this one, but we're getting into the really meaty stuff in this post so if you can get past this, the rest will be a breeze.
Tip1: Small, Focused Unit Tests
One of the best pieces of advice I've seen regarding unit tests is to keep each individual test method small and focused. This makes your code (the code you're testing, and the actual production code) easier to maintain, due to simplification and clarity of purpose. Could I be more vague? Probably, but I'm not paid by the word so let's see an example:
(Production code)
public int AddStuff(int? param1, int? param2)
{
if (!param1.HasValue || !param2.HasValue)
return -1;
else
return param1.Value + param2.Value;
}
(Focused unit testing)
[TestMethod]
public void AddStuffNullParams()
{
var actual = new Class1().AddStuff(null, null);
Assert.AreEqual(-1, actual, "AddStuff should return -1 when both parameters are null");
}
[TestMethod]
public void AddStuffNullParam1()
{
var actual = new Class1().AddStuff(null, 3);
Assert.AreEqual(-1, actual, "AddStuff should return -1 when the first parameter is null");
}
[TestMethod]
public void AddStuffNullParam2()
{
var actual = new Class1().AddStuff(4, null);
Assert.AreEqual(-1, actual, "AddStuff should return -1 when the second parameter is null");
}
[TestMethod]
public void AddStuffValidNumbers()
{
var actual = new Class1().AddStuff(4, 3);
Assert.AreEqual(7, actual, "AddStuff should return the sum of 2 numbers when numbers are passed in");
}
(Mosh pit unit testing)
[TestMethod]
public void AddStuffTests()
{
var actual1 = new Class1().AddStuff(null, null);
Assert.AreEqual(-1, actual1, "AddStuff should return -1 when both parameters are null");
var actual2 = new Class1().AddStuff(null, 3);
Assert.AreEqual(-1, actual2, "AddStuff should return -1 when the first parameter is null");
var actual3 = new Class1().AddStuff(4, null);
Assert.AreEqual(-1, actual3, "AddStuff should return -1 when the second parameter is null");
var actual4 = new Class1().AddStuff(4, 3);
Assert.AreEqual(7, actual4, "AddStuff should return the sum of 2 numbers when numbers are passed in");
}
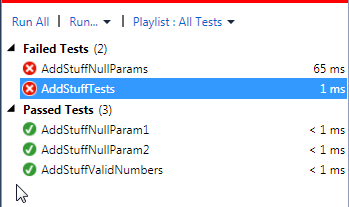
Now pretend somebody comes along and breaks the production code such that if both parameters are null, it starts throwing an exception. It might not seem like a big deal, but with the mosh pit unit test method you have a harder time telling what went wrong. You lose some extra time debugging the problem due to not knowing what could have happened. The error you get for the more focused unit tests is however more useful, as you can see in the screenshot below:
Yeah it's not a huge deal really, but every bit of assistance helps. The name "AddStuffNullParams" lets you know that the method no longer works properly when you have null params. The name "AddStuffTests" really tells you nothing and you have to dig a little longer to get to the same depth. Smaller and more focused methods also means less chance of ripple effects when you modify things, so it's a no-brainer.
Tip2: Dependencies, Dependency Injection (DI), and Mocks
What is Dependency Injection? Dependency Injection is just a fancy way of saying that you pass dependencies your code has, into your code. DI can easily be a full blog post of it's own, but I have to keep things short to account for my meager attention span so we'll just cover a quick scenario: You need to access a database in your code to pull in some data, so you write a method to pull in the data. You then write some other code to process that data. Now you wish to unit test the code that is processing the data...woops! Your code hits a database, so how in the world are you going to exercise that code with a unit test? It really adds no value to your tests to hit the database, as it's 1) comparatively slow, 2) volatile, and 3) difficult to setup test data. This is a problem that comes up fairly often with accessing external resources such as databases, files, web services, and many other things. Your unit tests should not exercise these external dependencies, they should exercise only your own code. Dependency Injection is your friend in these cases! First, here is some code that returns true if there are rows in a table. It directly accesses the table via a sql connection/command.
public class DataProcessor
{
public bool ProcessData()
{
using (var conn = new SqlConnection("some conn string"))
{
var cmd = conn.CreateCommand();
cmd.CommandText = "select count(1) from tblSomeTable";
cmd.CommandType = System.Data.CommandType.Text;
using (var reader = cmd.ExecuteReader())
{
if (reader.Read())
return true;
}
}
return false;
}
}
How would you unit test this? Well you could go through the trouble to setup sample data in the database at the beginning of a positive test and a negative test (one test where the db has data, one test where it doesn't), but you don't really care to test the data itself; just the code. So, instead you would pass in the data dependency using an interface and a mock.
public class DataProcessor
{
private IDataRetriever m_dataRetriever;
public DataProcessor(IDataRetriever dataRetriever)
{
m_dataRetriever = dataRetriever;
}
public bool ProcessData()
{
return m_dataRetriever.HasData();
}
}
First we see the revamped DataProcessor class. It now has a constructor which accepts an object of type IDataRetriever. The method ProcessData then uses this data retriever object to pull the data, and does what it needs to do based off of that call.
public interface IDataRetriever
{
bool HasData();
}
Here's the interface for IDataRetriever; short and sweet.
public class ConcreteDataRetriever : IDataRetriever
{
public bool HasData()
{
using (var conn = new SqlConnection("some conn string"))
{
var cmd = conn.CreateCommand();
cmd.CommandText = "select count(1) from tblSomeTable";
cmd.CommandType = System.Data.CommandType.Text;
using (var reader = cmd.ExecuteReader())
{
if (reader.Read())
return true;
}
}
return false;
}
}
And here is a concrete implementation of that IDataRetriever interface. This class is now responsible for communicating with the database, not our DataProcessor class.
[TestClass]
public class DataProcessorTest
{
[TestMethod]
public void ProcessDataTrue()
{
var dp = new DataProcessor(new DataRetrieverMock() { EmulateHasData = true });
Assert.IsTrue(dp.ProcessData(), "DataProcessor should have data");
}
[TestMethod]
public void ProcessDataFalse()
{
var dp = new DataProcessor(new DataRetrieverMock() { EmulateHasData = false });
Assert.IsFalse(dp.ProcessData(), "DataProcessor should not have data");
}
}
class DataRetrieverMock : IDataRetriever
{
public bool EmulateHasData { get; set; }
public bool HasData()
{
return EmulateHasData;
}
}
Now, through the magic of DI we are able to write unit tests that exercise the method ProcessData without hitting the database! You can see in the above 2 test methods when we create an instance of DataProcessor, we also pass in a brand new instance of DataRetrieverMock. DataRetrieverMock is a concrete implementation of IDataRetriever (just like ConcreteDataRetriever is) that doesn't actually hit the database. Yay dependency injection!
You may also be thinking to yourself "hey, with the logic code (the class DataProcessor) decoupled from the data retrieval code (IDataRetriever and DataRetriever), I bet it would be easier to switch out the data storage mechanism huh?" Well you're right! that's another side benefit of DI; in general, it keeps your external dependencies separate from the business logic, so if you need to retrieve the same data from somewhere else you just write another Concrete implementation of the external retriever interface. Spifferiffic!
What's Next?
I think your time would best be spent Christmas shopping, so get that out of the way. Come back refreshed next week for part 4.
References
http://msdn.microsoft.com/en-us/library/ms182517(v=vs.100).aspx